
在当今科技飞速发展的时代,脑科学与人工智能的融合正催生出一项极具潜力的前沿技术——类脑计算,它有望开启人类智能与机器智能深度融合的新纪元,彻底改变人与世界的交互方式以及对智能的认知。
类脑计算是脑科学与人工智能深度融合的产物,它旨在借鉴大脑的神经结构和信息处理机制,构建更加高效、智能的计算系统。类脑计算的核心理念是让机器像大脑一样思考和学习,通过模拟大脑的神经元网络和突触可塑性,实现对复杂信息的并行处理和自适应学习。
脑虎科技创始人兼CEO彭雷此前在接受第一财经采访表示,长远来看,脑机接口研究的终极目的就是AI(人工智能)与HI(人类智能)的深度融合,探索人类与机器之间更高效、更直接的交互方式。
类脑计算——下一代人工智能网络:低能耗,高效率
本轮由ChatGPT引发的人工智能浪潮是基于人工神经网络(Artificial Neural Networks,ANNs)架构,通过庞大的训练数据集和高度复杂的结构,让人工智能在语言理解、生成以及推理方面取得了重大突破。
庞大的数据量意味着频繁且大规模的运算,随之而来的是对算力需求的迅猛增长,受制于硬件的供应量,人工智能的进一步发展面临“算力荒”的瓶颈,优化运行效率和降低计算资源消耗成为人工智能未来发展的一个关键方向。
事实上,人工神经网络是受大脑启发,但在结构、神经计算和学习规则方面与大脑的生物神经网络有着根本的不同:大脑的神经元连接是稀疏的,每个神经元只与少数其他神经元连接,这种稀疏连接方式使得大脑能够在低能耗的情况下高效处理信息;人工神经网络通常采用完全连接的方式,每个神经元与前一层和后一层的所有神经元连接,这种连接方式虽然能够模拟人脑处理信息的方式,但导致了极高的能耗。
人工神经网络的能耗非常高,尤其是大型模型。例如,训练GPT-3模型需要大约1287兆瓦时(128.7万度)的电力,相当于美国约121个家庭一整年的用电量。根据相关研究,大脑的总功耗仅为20瓦左右,却能够运行非常复杂且庞大的神经网络。
这意味着如果人工神经网络可以模仿大脑稀疏型的链接方式,优化计算模型,将大幅降低能耗。类脑计算通过模拟生物大脑的工作方式,为实现低功耗、低成本且能够实时在线学习的人工智能系统提供了新的解决方案。
脉冲神经网络(Spiking Neural Network,SNN)作为类脑智能的核心计算架构,其工作原理更接近生物神经元的信号传递,以脉冲形式的信号和时间序列信息进行通讯,支持异步且稀疏的事件驱动方式。相较于人工神经网络(ANN),脉冲神经网络(SNN)有低能耗的显著优势。

类脑计算的核心目标是通过学习生物神经系统的结构、功能和机制,进而构建相应的计算理论、芯片体系结构以及应用模型与算法。不同于传统冯·诺依曼存算分离的特性,类脑计算基于仿生的脉冲神经元实现信息的高效处理,具有低功耗、低延迟的技术优势,在边缘计算和实时控制等领域具有广泛的应用价值和潜力。
关键核心硬件——类脑芯片仍待技术突破
类脑计算的技术发展基于硬件平台、软件平台、模型算法和基准数据协同设计和应用。其中硬件平台的核心就是神经形态芯片和新型存储器。
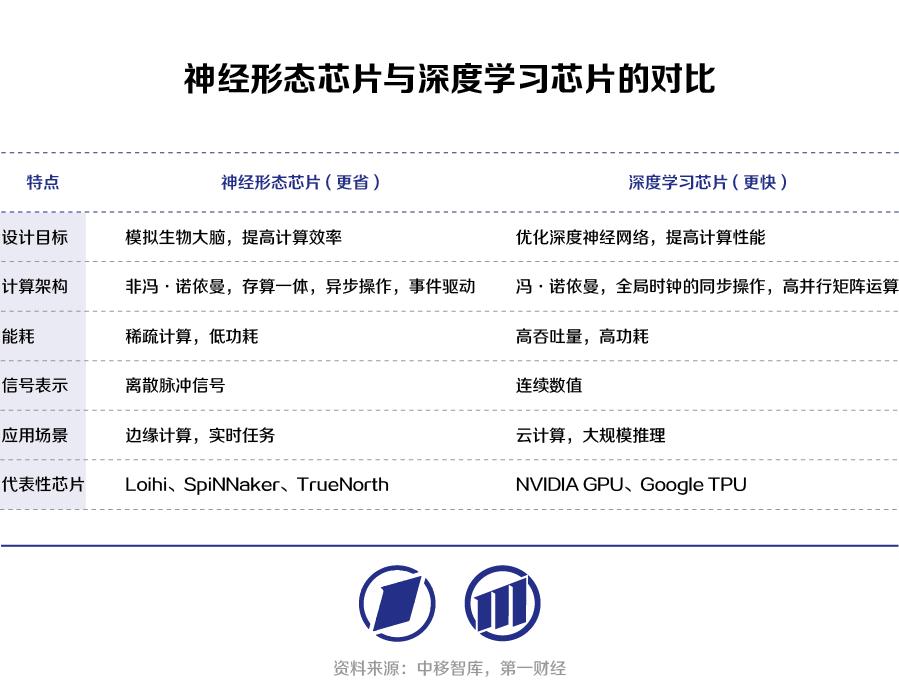
传统的深度学习芯片依赖于冯·诺依曼架构,具有复杂的处理单元和相应的存储器层次结构,专注于对ANN的执行优化。而神经形态芯片则通常采用非冯·诺依曼分散式多核架构,其中每个核心都将计算与内存紧密耦合。
深度学习芯片追求的是“更快”,更多考虑提高处理速度和计算能力,即性能优先;而神经形态芯片追求“更省”,强调能效比,即效率优先。
新型存储器主要指忆阻器,它结构简单、集成密度高,理论上一个就可以实现神经突触的功能,可极大地提升突触密度,是从硬件层面实现类脑神经网络的高效方式之一。
目前神经形态芯片可分为两大类,一类是仅支持SNN架构,例如IBM TrueNorth、英特尔Loihi、达尔文芯片等;另外一类则支持SNN和ANN的混合计算架构,例如天机芯、英特尔Loihi2、领启KA200等。
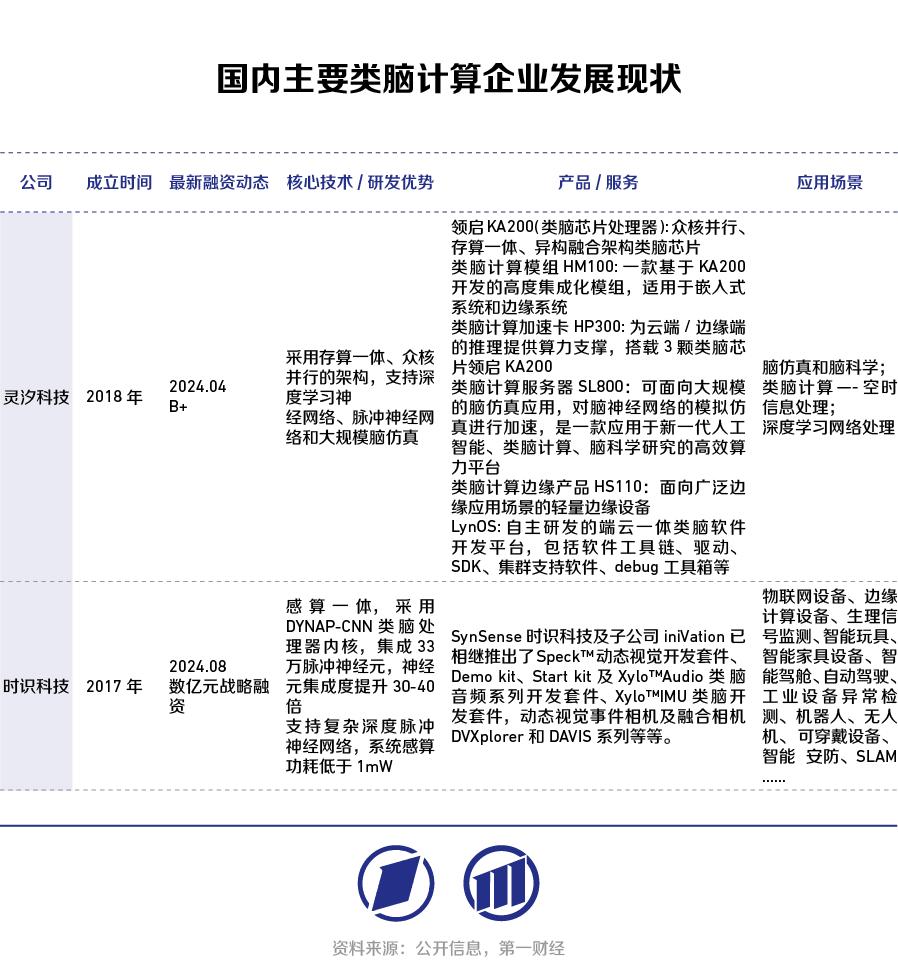
其中达尔文芯片、天机芯、领启KA200是由浙江大学、清华大学、中科院牵头研发的类脑芯片。
由浙江大学牵头研发的达尔文3芯片于2023年发布,相比较达尔文2大幅提升了突触密度和规模,单芯片能够支持超过200万个神经元和1亿个神经突触。
在异构融合类脑芯片领域,由清华大学类脑计算研究中心研发的天机芯是全球首款异构融合类脑芯片。该芯片于2019年8月1日作为封面文章发表在国际顶级学术期刊《自然》(Nature)上,实现了中国在芯片和人工智能两大领域《自然》论文的零突破。
神经形态芯片虽具优势,但取代传统深度学习芯片还为时过早。
首先,人类对大脑的架构和功能仍知之甚少,现有的神经元和突触模型可能忽略了大脑功能的重要方面,这种对生物系统的不完全理解使得神经形态芯片的设计目标存在不确定性,增加了研发的难度和成本。
其次,神经形态芯片需要模拟生物神经元和突触的行为,但现有技术难以同时满足高性能和低功耗的要求。例如,忆阻器虽然能够模拟突触的可塑性,但其非线性电阻变化和器件集成的复杂性仍是未来需要解决的问题。此外,大规模突触阵列的实现也受到器件设计难度和集成复杂度的限制。
短期看,神经形态芯片制造成本高,生态系统尚未完全成熟,大规模推广仍面临挑战。通用计算和大型模型训练中,CPU/GPU仍不可或缺,未来神经神态芯片与深度学习芯片将互补发展。
中国移动集团首席专家钱岭在接受第一财经采访时表示,类脑计算目前仅适用于实时处理和低功耗计算等特定领域,且大都处于实验室阶段,离大规模实用化仍有距离。
类脑计算下游应用不断拓展
尽管目前类脑计算仍处于早期阶段,但随着人工智能技术的不断成熟和普及,类脑计算作为一种传统计算的高能效替代方案,对于推动人工智能时代的下一波浪潮具有巨大潜力。
据产业研究机构中研普华的《2023-2028年中国类脑计算行业深度分析与发展前景预测报告》,2022年全球类脑计算芯片市场规模约为1.78亿元人民币,中国市场规模也相当可观,并且呈现出快速增长的趋势。预计到2030年,中国类脑计算芯片市场规模将接近98亿元人民币(约14亿美元)。
随着类脑芯片的技术突破、大规模仿真平台的构建,类脑计算的下游应用也将从低维度信息处理和高速视觉处理向端侧可穿戴设备、摄像头和终端设备拓展。
在医疗领域,类脑计算可用于治疗神经系统相关的疾病并帮助残疾人士恢复行动能力;在智能家居、自动驾驶、机器人等领域,类脑计算也将发挥重要作用。在此基础上,未来将加入在复杂环境中的实时决策能力,在无人机和自动驾驶领域有很大的应用前景。

(本文来自第一财经)
还没有评论,来说两句吧...