
衡宇 发自 凹非寺
量子位 | 公众号 QbitAI
DeepSeek-R1慢思考、长推理的表现,展现了训练步骤增加,会导致长CoT的涌现。
它通过模拟人类思维逐步推导答案,提升了AI大模型的推理能力和可解释性。
但长CoT的触发条件是什么?怎么做能优化它?像个黑盒,还没研究明白。
来自清华、CMU和IN.AI的研究团队,近期专门探究了长CoT在大模型中的工作机制和优化策略。

先把该研究得出的4点发现给大家呈上来:
这篇论文开始被网友疯转,并被感慨道:这可太酷啦!
还有网友表示,不出所料,奖励函数果然很重要~
从SFT和RL两方面研究长CoT
研究团队明确表示:
我们的目标是揭开大模型中长CoT推理的神秘面纱。
通过系统分析和消融,提取关键见解,并提供实用策略来增强和稳定其性能。

团队采用了2款基础模型:
同时采用了4个代表性推理基准:
MATH-500、AIME 2024、TheoremQA和MMLU-Pro-1k。
默认情况下,温度t=0.7、顶部−p值=0.95,最大输出长度=16384 tokens。
而具体过程,从SFT(监督微调)和RL(强化学习)两方面下手。
研究人员默认使用MATH的7500个训练样本提示集来提供可验证的真值答案。
SFT对长CoT的影响
团队首先探究了SFT对长CoT的影响。
通过在长CoT数据上进行SFT,模型能够学习到更复杂的推理模式。
但目前而言,短CoT更为常见,这就意味着针对其收集SFT数据相对简单。
鉴于此,团队选择用阿里通义的QwQ-32B-Preview来提炼长CoT,用阿里通义的Qwen2.5-Math-72B-Struct来提炼短CoT。
具体来说,研究人员先对每个prompt的N个候选响应进行采样,然后筛选出具有正确答案的响应。
对于长CoT,使用N∈{32, 64, 128, 192, 256};对于短CoT,使用N∈{32, 64, 128, 256},(此处为了提高效率跳过了一个N)。
在每种情况下, SFT标记的数量都与N成正比。
如下图虚线所示,随着扩大SFT的token,对长CoT进行SFT,会继续提高模型准确性;而对短CoT来说,SFT带来的效益在很早就达到饱和。
譬如在MATH-500上,长CoT SFT的准确率超过70%,tokens达到3.5B时仍然没有进入瓶颈期。
相比之下,短CoT SFT的tokens从约0.25B增加到1.5B,准确率仅产生了3%的增长。
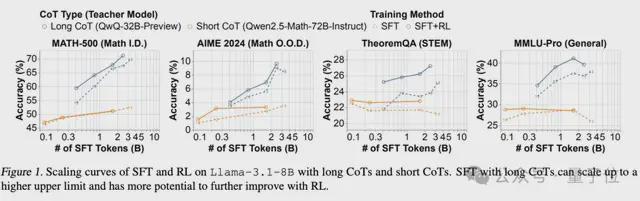
实验结果显示,长CoT SFT能够显著提高模型的性能上限。
而且,在达到更高性能的同时,还有比短CoT更高的性能拓展空间。
RL对长CoT的影响
由于业内普遍认为RL的上限高于SFT,团队将长CoT和短CoT视为针对RL的不同SFT初始化方法进行比较。
研究人员使用SFT检查点来初始化RL,并训练了四个epoch,每个prompt生成四个响应。
此外,团队把PPO和来自MATH数据集的基于规则的验证器训练拆分,作为RL的提示集。
具体结果同样在下图中显示出来:
图中实线和虚线之间的间隙表明,使用长CoT SFT初始化的模型通常可以通过RL进一步显著改进,而使用短CoT SFT初始化的模型从RL中获得的收益很小。
例如,在MATH-500上,RL可以将长CoT SFT模型绝对改进3%以上,而短CoT SFT模型在RL前后的精度几乎相同。
需要注意的是,RL并不总是能够稳定地扩展思维链的长度和复杂性。
为此,研究团队引入了一种带有重复惩罚的余弦长度缩放奖励机制,有效稳定了思维链的增长,并鼓励模型在推理过程中进行分支和回溯。
整理长CoT数据
除上述研究外,为了整理长CoT数据,研究团队比较了两种方法。
一种是通过提示短CoT模型,生成原始动作,并按顺序组合它们,以此构建长CoT轨迹。
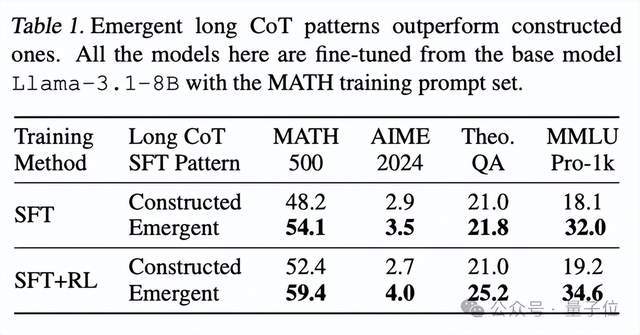
另一种是从现有的长CoT模型中提炼出长CoT轨迹——这些模型表现出涌现长CoT(emergent long CoT)。
结果表明,从涌现长CoT模式中提炼出来的模型,比构建的模式泛化得更好,并且可以用RL进一步显著改进。
在构建模式上训练的模型则不能做到这一点。
此外,由于DeepSeek-R1已经证明,在基础模型上扩展RL计算可以出现长CoT,自我验证行为有时会被模型的探索标记为紧急行为或 “顿悟时刻”。
这种模式在短CoT数据中很少见,但研究人员注意到,有时基座模型已经存在自我验证行为,而用RL强化这些行为需要严苛的条件。
如下图所示,Qwen2.5Math-7B的RL有效地提高了准确性,但没有增加基础模型输出中存在的 “recheck” 模式的频率,也没有有效地激励其他反射模式,如 “retry” 和 “alternatively”。
这表明尽管提高性能效果显著,但来自基座模型的RL不一定会激励反射模式。
四个关键发现
在系统性研究了长CoT推理的机制后,团队提出了4个关键发现。
第一,SFT并非必需,但能简化训练并提高效率。
虽然SFT并非训练长CoT的必要条件,但它能够有效地初始化模型,并为后续的RL训练提供坚实的基础。
第二,推理能力随着训练计算的增加而出现,但并非总是如此。
长CoT的出现并非必然,且朴素的RL方法并不总是能有效地延长CoT长度。
需要通过奖励塑造等技巧来稳定CoT长度的增长,团队的做法是引入了一种余弦长度缩放奖励,并加入了重复惩罚,这既平衡了推理深度,又防止了无意义的长度增加。

第三,可验证奖励函数对CoT扩展至关重要。
由于高质量、可验证数据稀缺,扩展可验证奖励函数对RL至关重要。
论文探索了利用网络提取的包含噪声解决方案的数据,并发现这种“银色”监督信号在RL中展现出巨大的潜力,尤其是在处理OOO任务(如STEM推理)时。
第四,基模型中天生存在错误修正和回溯等技能,但通过RL有效地激励这些技能需要大量的计算。
而测量这些能力的出现需要更精细的方法,需要谨慎设计RL激励。

最后,研究团队提出了几个未来的研究方向,包括:
扩大模型规模、改进RL基础设施、探索更有效的验证信号以及深入分析基础模型中的潜在能力。
这些方向有望进一步推动长CoT在大模型中的应用。
参考链接:
[1]
[2]
— 完 —
还没有评论,来说两句吧...