
【文/观察者网专栏作者 潘攻愚】
DeepSeek“小扣发大鸣”,半年多的时间,不但从LLM通用模型的V2迭代到了V3,而且进一步推出了主打推理能力的R1模型。从训练成本、架构调整和开源模式等多个维度技惊全球,引发了一股山呼海啸般的赞誉。春节期间大洋彼岸资本市场的大幅震荡以及开年后国内“DeepSeek概念股”的大涨,让这一现象持续成为坊间热议的焦点。
DeepSeek的成功,顺应了pre-training到推理的AI大模型的必然演化过程。DeepSeek的崛起为何是顺天应时之举?不妨先来看两段话。
去年2月下旬,英伟达CEO黄仁勋接受美国科技媒体Wired采访时说:“英伟达今天的业务可能是40%的推理和60%的训练,这是一件好事,因为这让你意识到AI终于成功了。如果英伟达的业务是90%的训练和10%的推理,你可以说AI仍处于早期研究阶段。”
去年12月,OpenAI的CFO Sarah Friar在接受科技媒体《信息》(The Information)采访时说:“OpenAI的ChatGPT Pro开放给C端用户的套餐每月200美元,实在是太便宜了,它合理的价格应该是每月2000美元。”进一步结合她上下文采访的言外之意,她主要是说OpenAI“心善”,秉承一股AI为大众平权服务的道义感,才没把价格搞得那么高。今天,他们这种伪善的画皮在DeepSeek R1开源模型面前彻底被撕下。
这两段话相当有代表性,一个指向AI技术应用的演进方向,一个则事关AI推训模式落地的商业化问题,这两个层面的问题相互缠绕,互为表里。
就在OpenAI牵头搞“星际之门”,将算力的Scale Law延伸到了民间资本市场和国家投资领域,试图把AI产业和美国国运绑定之时,DeepSeek对其做了一个釜底抽薪式的叙事消解。
众声喧哗之下,来自大洋彼岸的质疑,甚至是带有恶意性质的诋毁同样值得关注。
分析美国AI大模型行业某些头面人物带有惊慌失措心理的评论,可以进一步深化我们对DeepSeek到底真正打到了对方哪些痛处的认知。大洋彼岸的详细分析数据和质疑声音,以知名半导体咨询机构Semianalysis总裁Dylan Patel和Anthropic的CEO Dario Amodei为代表性,这两家的文章在中文互联网世界被翻译后大量转载。

Anthropic的CEO Dario Amodei
他们主要从GPU囤货、成本测算、非技术性营销、以及模型数据蒸馏不合规等四个角度,试图告诉公众DeepSeek的突破其实没那么“硬核”。
一、摇唇鼓舌DeepSeek囤货“敏感性”高端GPU
按照Semianaylsis的测算,“DeepSeek大致拥有10000张H800 GPU芯片、10000张H100 GPU芯片,以及大量H20 GPU芯片”。
Dario Amodei在长文中转述了Semianaylsis的测算,认为DeepSeek手上拥有的用于训练和推理的Hopper架构的英伟达GPU卡(阉割版和非阉割版都算在内)差不多有5万张,这个量和美国主要头部的AI模型训练机构如OpenAI、Deepmind等差距在两三倍左右,结合基于合成数据(synthetic data generation)和强化学习进行推理能力提升的后训练(post-training)方法,他认为DeepSeek本来就站在巨人的肩膀上,又用了巨量的GPU,才有了今天的成果。
为什么Dario Amodei要用Semianaylsis的数据给自己拉大旗扯虎皮呢?
因为Dario Amodei心中有一个所谓的AI训练成本的“摩尔定律法”——每一年大约能降三到四倍,如果用强化学习的方法进行推理架构调整,可以把成本降到六至八倍,但这个就是降成本的极限了。按照这种成本测算假说推断,DeepSeek有五万张Hopper卡。
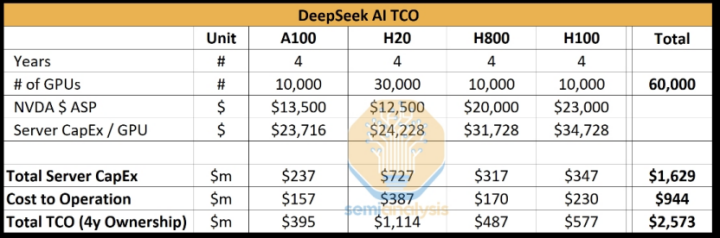
那么,如果我们进一步追问,Semianaylsis认为DeepSeek手上有这么多高端GPU卡,他们是怎么算出来的?他们采用了一种类似归谬法的推理:Anthropic单单训练一个Claude 3.5 Sonnet的成本就高达数千万美元,如果DeepSeek有如此神之一手能强力降本,Anthropic何必煞费苦心去找亚马逊融资数亿呢?
有关Anthropic到底是怎么花费投资人的钱的问题,也许马斯克手下的DOGE(政府效率部)更有兴趣回答。相比微软、谷歌一派,代表云服务商亚马逊一派的Anthropic CEO按耐不住跳出来写长文的主要原因之一,是深刻觉察到在十万到百万级GPU基础上的生态进行推训,他们的Claude系列总价格是最高的,总性价比也是最低的。
DeepSeek合法拥有的H800,相比H100,主要是阉割了NVLink的通信带宽;H20虽然也是阉割版,单卡算力仅有H100的20%,但H20可以通过多卡堆叠模式,其HBM容量(96GB)甚至高于A100/H100(80GB)。换言之,H20的显存带宽可以让DeepSeek的Decode阶段每生成1个Token所需时间低于A100和H100。
DeepSeek把阉割版用出了禁运版所没有的功效,让Dario Amodei居然发出了应该对中国大陆进一步加强GPU管制的恶意言论,这也许才是他抨击DeepSeek的目的。
从话语体系上讲,Semianalysis用Anthropic缺乏公允性的AI模型训练成本反推DeepSeek有可能绕开管制,非法持有高端GPU,而Anthropic反过来用Semianalysis建立在沙堆之上的推论来论述DeepSeek在成本问题上并无过人之处,这其实是一个合谋式的循环论证。
还没有评论,来说两句吧...