
最近,有个爆火的话题:LLM学会教自己预测未来了!
像神秘的预言家一样,预测未来的天气、某部电影的票房成绩,甚至是股市走势,听起来是不是特别像科幻电影里的情节?
来自Lightning Rod Labs和伦敦政治经济学院的研究者对提升LLM预测未来的能力展开了研究。

论文链接:
人类专家在预测时,会综合考量大量的信息,包括各种事实、发展趋势,以及相互矛盾的证据等,经过复杂的分析和思考,才能做出较为准确的预测。
在金融领域,准确的市场预测能够帮助投资者把握时机,做出明智的投资决策,实现财富的增长。
在商业领域,对市场需求和产品趋势的预测,能让企业提前布局,推出更受消费者欢迎的产品,占据市场优势。
为了提升LLM的预测能力,科研人员进行了诸多尝试,采用了数据聚合、新闻检索、模型微调等多种方法。
这些方法在一定程度上确实提高了模型的预测性能,但它们存在一个共同的问题——过度依赖人工整理的数据。
比如,需要借助最新的大众预测结果,或者依赖人工筛选的内容。而且,模型往往无法从已经确定结果的事件中学习经验,实现自我提升。
获取人工数据成本高昂,效率也较低,使得模型难以持续学习和进步。
LLM的「自学秘籍」
研究人员提出了一个结果驱动的微调框架,让LLM能够摆脱对人工输入的过度依赖,通过自我学习来提升预测能力。
让模型「自我博弈」,生成多样化推理轨迹和概率预测。根据这些推理预测与实际结果的接近程度,对推理组合进行排序。最后,利用直接偏好优化(DPO)技术对模型进行微调。

数据与新闻收集
研究人员从预测市场Polymarket收集了多达12100个具有二元结果的预测问题,像「奥特曼会参加总统就职典礼吗?」「FTX在2024年会停止付款吗?」。
研究者筛选数据,排除了那些结果不明确的问题,并将剩余数据划分为训练集和测试集。
训练集包含9800个问题,其结果在2024年7月1日至12月15日期间确定;测试集则有2300个问题,结果在2024年12月25日至2025年1月23日揭晓。

将事件未发生标记为「0」,发生标记为「1」。为了评估模型预测的准确性,研究人员引入了Brier分数(BS)这一指标,分数越低,代表预测越准确。
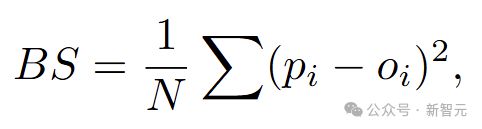
其中N代表预测问题数量。
在答案揭晓前14天,研究人员借助NewsCatcher API收集新闻。先通过GPT-4o生成搜索查询,再利用Newscatcher等外部新闻检索服务,对相关新闻进行聚合和处理。
这些新闻将为后续模型的自我学习和预测提供重要的支持。
模型Self-Play数据生成
研究者选用了Phi-4 14B和DeepSeek-R1 14B这两个模型。别看参数只有14B,在一般科学和编程基准测试中,表现十分出色。
研究人员让这两个模型针对每个问题进行推理,并给出最终的概率预测。
对于Phi-4 14B模型,采用scratchpad提示法,就像给它提供了一个草稿本,便于逐步展示推理过程。DeepSeek-R1 14B模型由于输出中已有 标签,所以使用零样本提示法。
提示内容不仅有问题本身,还包含收集到的新闻摘要。每个问题都会生成一对推理轨迹,具体做法是先生成一个推理和预测,然后最多重新运行四次,以获得第二个不同的预测。若后续预测都相同,则舍弃这组预测。
最终,为9427个预测问题,生成了18854条推理轨迹。
基于结果的重新排序
生成推理轨迹和预测结果后,需要根据预测与实际结果的接近程度进行重新排序。
研究人员定义了一个排序指标,通过计算预测概率与实际结果的绝对差值来衡量两者的接近程度。
例如,若实际结果为0,一个预测概率是4%,另一个是8%,那么概率为4%的预测推理轨迹排名更高。这样,模型就知道哪些推理方式能带来更准确的预测。
此外,为了排除新闻聚合信息对排序的影响,研究人员还微调了一组标签随机化的控制模型,通过对比,来确定模型的学习效果是否源于更准确的预测依据。
直接偏好优化(DPO)微调
研究人员使用直接偏好优化(DPO)方法对Phi-4 14B和DeepSeek-R1 14B进行微调。
这种方法无需训练单独的奖励模型,而是直接从模型自我博弈生成的排序推理对中学习奖励信号。即使单个预测并不完美,DPO也能通过成对比较,发现预测之间的细微质量差异,系统地纠正偏差。
与传统的监督微调(SFT)相比,SFT依赖人工挑选的示例,并视其为完全正确,容易丢弃有价值的信息。DPO则能从所有样本中学习,显著提高了微调过程的稳健性和效率。
在微调过程中,研究人员使用LoRA适配器,对参数进行了精心调整,如设置合适的学习率、使用AdamW优化器、采用BF16混合精度等,用8个H100 GPU训练。
Phi-4 14B在第五轮训练时效果趋于稳定,而DeepSeek-R1 14B在第四轮就达到了稳定状态。
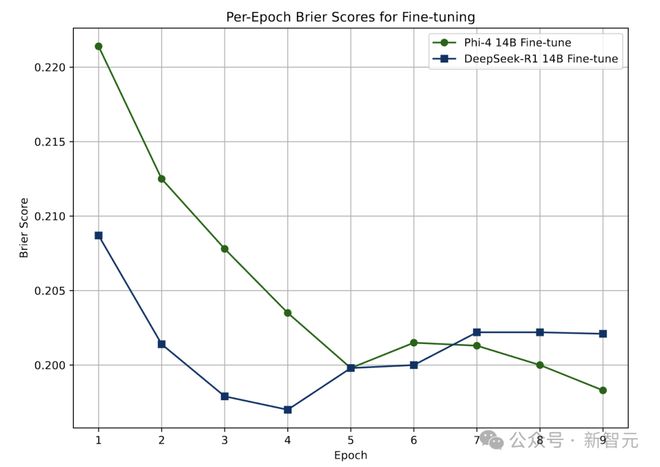
最后,用一个包含2300个问题的测试集来检验模型的学习成果。
这个测试集的问题结果在训练集最后一个问题结果出来10天后才揭晓,确保微调后的模型没有接触过与测试集相关的新闻信息,以免影响测试结果。
每个模型都以原始基础模型、使用正确结果微调的模型,以及使用随机结果微调的对照模型这三个版本参与测试。这样可以清晰地区分模型的学习效果是源于接触新信息,还是优化推理过程。
在测试时,针对不同模型设计了特定的提示。Phi-4 14B模型的提示就像一份详细的任务指南,引导它逐步思考。DeepSeek-R1 14B模型则被设定为专家角色,直接进行预测。
两个模型都会获得问题、问题背景、判断标准、当前日期、问题截止日期以及最多10篇新闻文章的摘要等信息。
最终,收集了每个模型对2300个问题的预测结果,模型均给出了有效的预测。

预测能力大幅提升
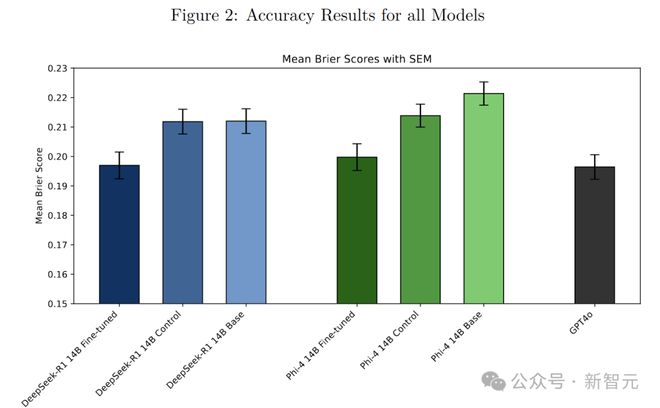
经过这一系列操作,Phi-4 14B和DeepSeek-R1 14的预测准确性有了显著提升。
Phi-4 14B和DeepSeek-R1 14B的预测准确率,比基础模型以及用DPO微调但标签随机化的对照模型提高了7-10%,在预测能力上能与GPT-4o这样的大型模型相媲美。
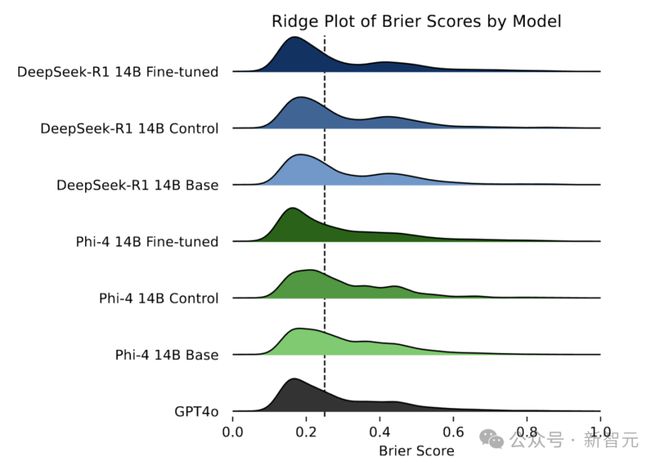
图中展示了每个模型的Brier分数核密度估计,较低的Brier分数表示较高的准确性。
Phi-4 14B微调后的平均Brier分数达到0.200,优于随机标签的对照模型(0.214)和基础模型(0.221)。DeepSeek-R1 14B微调后的平均Brier分数为0.197,同样超过了其对照模型(0.212)和基础模型(0.212)。
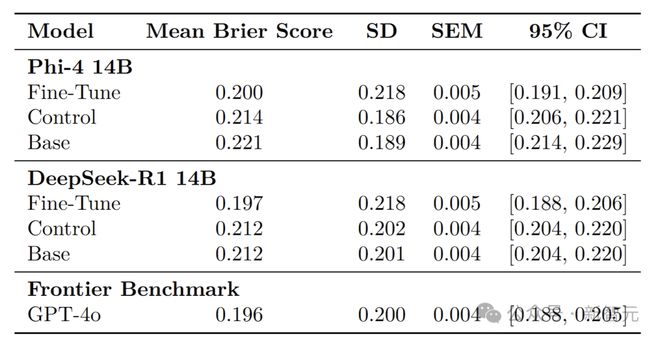
通过独立样本t检验发现,两个微调后的模型在预测准确性上都显著优于各自的基础和对照模型,并且在经过多重比较调整p值后,这一结论依然成立。
充分证明了该方法能够切实有效地提升模型的预测性能,而且这种提升并非源于微调时接触的额外信息。

与前沿模型GPT-4o相比,Phi-4 14B和DeepSeek-R1 14B虽然参数较少,但微调后的预测性能却与之相当。
在统计检验中,微调后的模型与GPT-4o之间没有显著差异。
进一步分析模型在不同问题上的预测准确性分布,可以发现微调后的模型虽然偶尔会出现一些准确性极低的预测(Brier分数高于0.5),但同时也能做出更多极其准确的预测(Brier分数低于0.05)。
以DeepSeek-R1 14B为例,微调后的模型有8.52%的问题Brier分数高于0.5,略高于基础模型(7.48%)和对照模型(7.61%);但有32.78%的问题Brier分数低于 0.05,远高于基础模型(23.22%)和对照模型(23.13%),Phi-4 14B也呈现出类似的趋势。
这项研究为LLM提升预测能力开辟了新的道路。
通过自我博弈和直接偏好优化,LLM能在不依赖大量人工标注数据的情况下,从实际结果中学习并改进预测,使小模型也能达到与大模型相媲美的性能,极大地提高了实用性和应用范围。
参考资料:
还没有评论,来说两句吧...