
IT之家 2 月 1 日消息,科技媒体 marktechpost 昨日(1 月 31 日)发布博文,报道称 Mistral AI 发布了 Small 3(全称为
Mistral-Small-24B-Instruct-2501)模型,共有 240 亿参数,实现了先进的推理能力、多语言支持和便捷的应用集成,并在多个基准测试中取得了令人瞩目的成绩。
该模型基于 Apache 2.0 许可证发布,允许开发者自由修改、部署和集成到各种应用程序中,对标 Meta 的 Llama 3.3 70B 和阿里巴巴的 Qwen 32B 等更大模型,官方声称在相同硬件上,提供超过三倍的性能。
Small 3 模型针对本地部署进行高效优化,在 RTX 4090 GPU 或配备 32GB RAM 的笔记本电脑上也能通过量化技术流畅运行。
模型在多样化的指令型任务上进行了微调,实现了高级推理、多语言能力和无缝应用集成,凭借 32k 的上下文窗口,它擅长处理长篇输入,同时保持高响应速度。
该模型还包含 JSON 格式输出和原生函数调用等功能,使其非常适合对话和特定任务的实现。
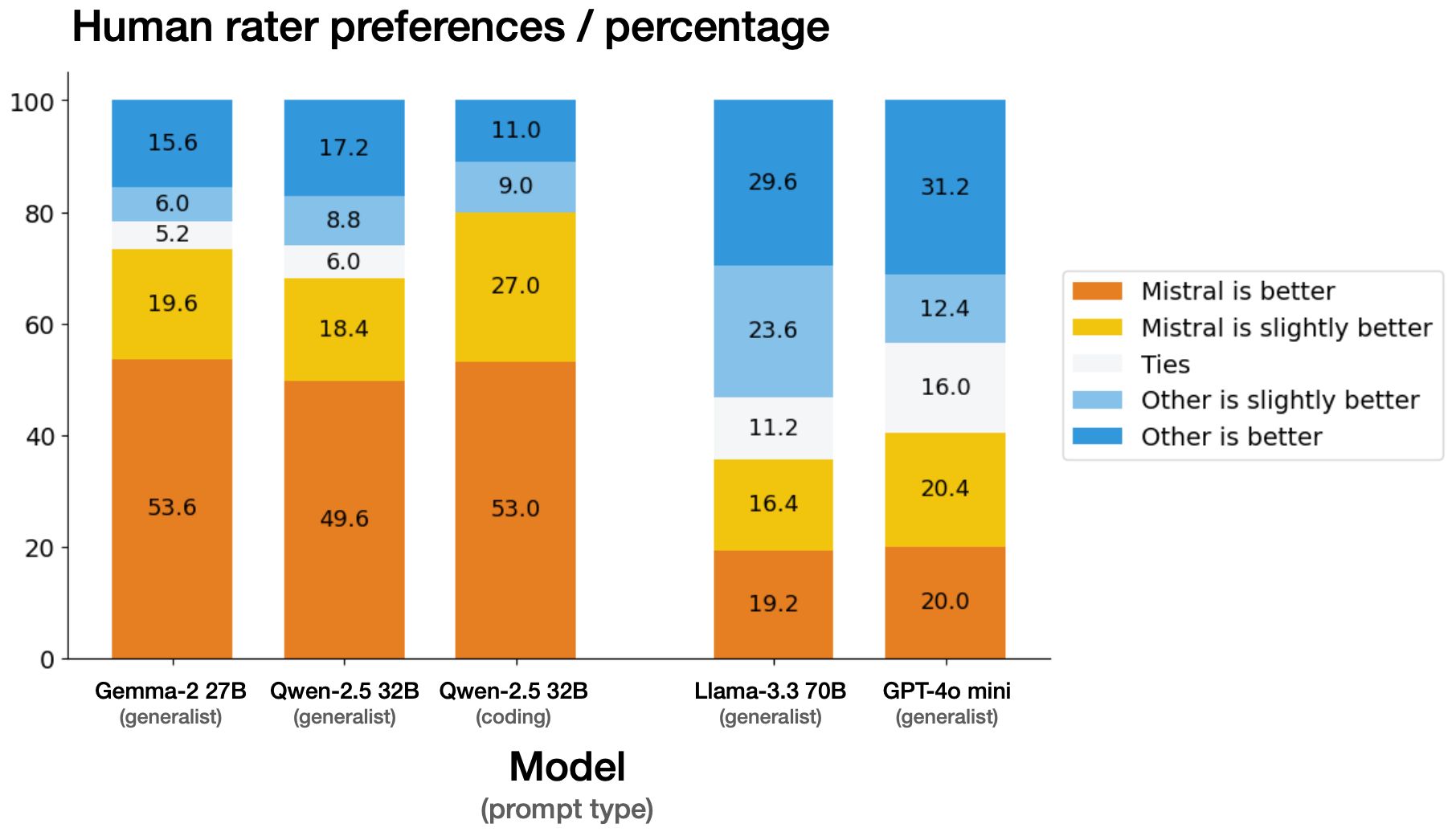
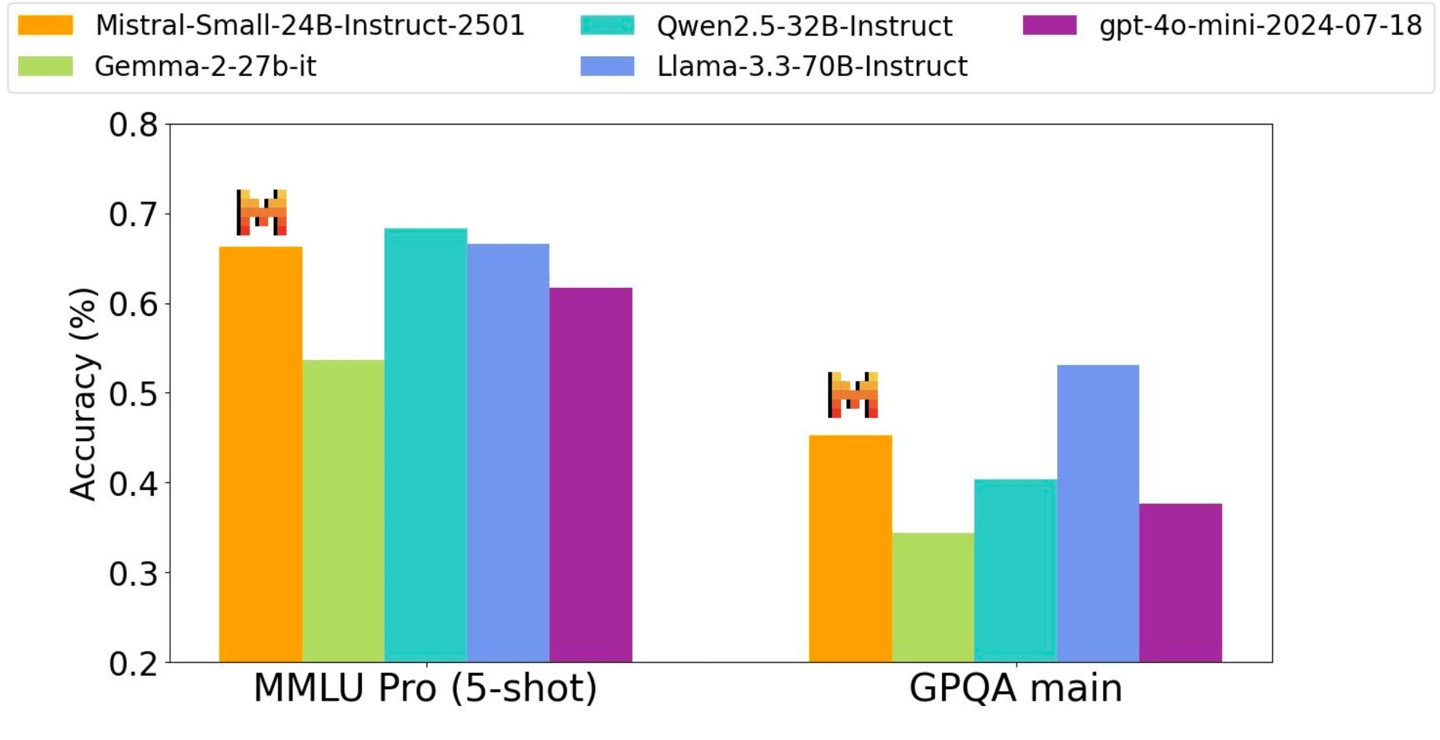
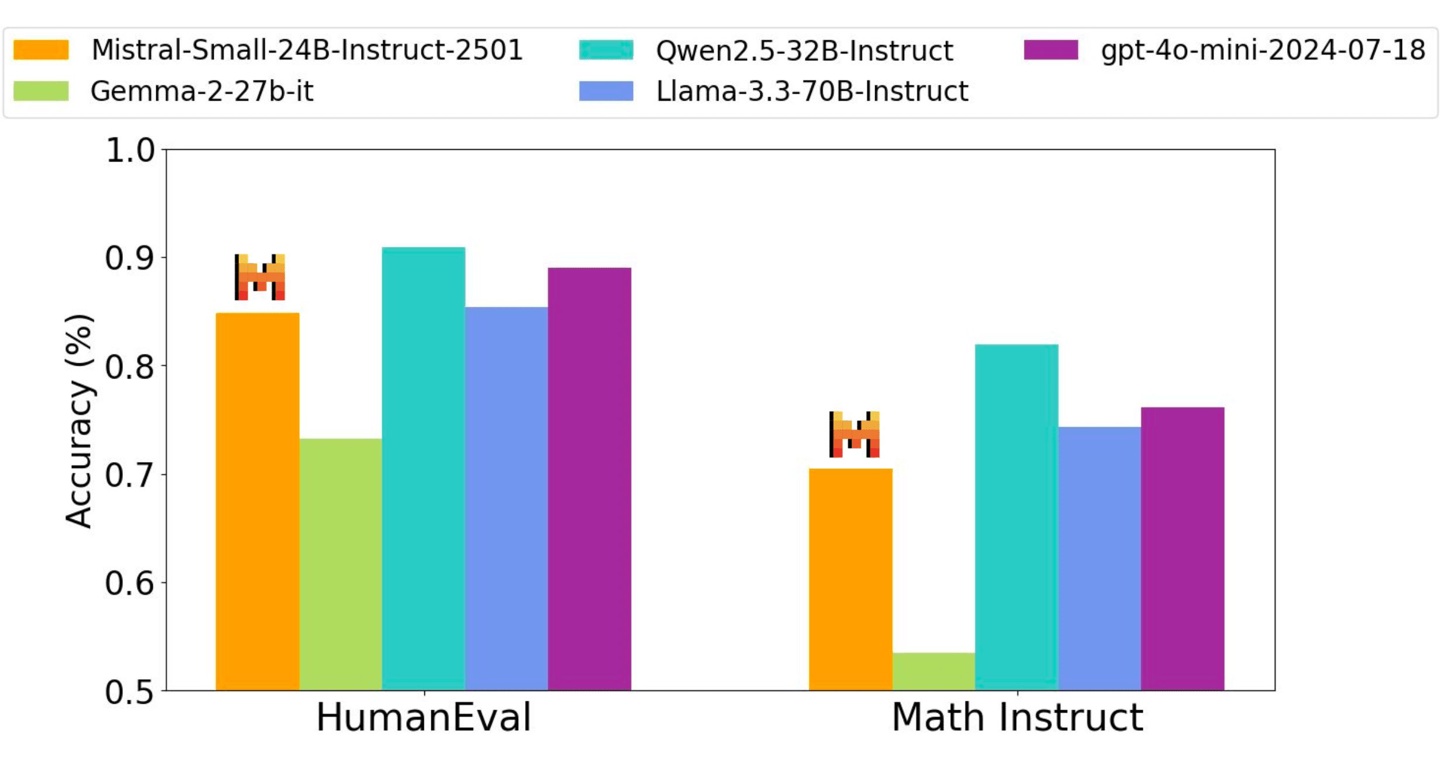
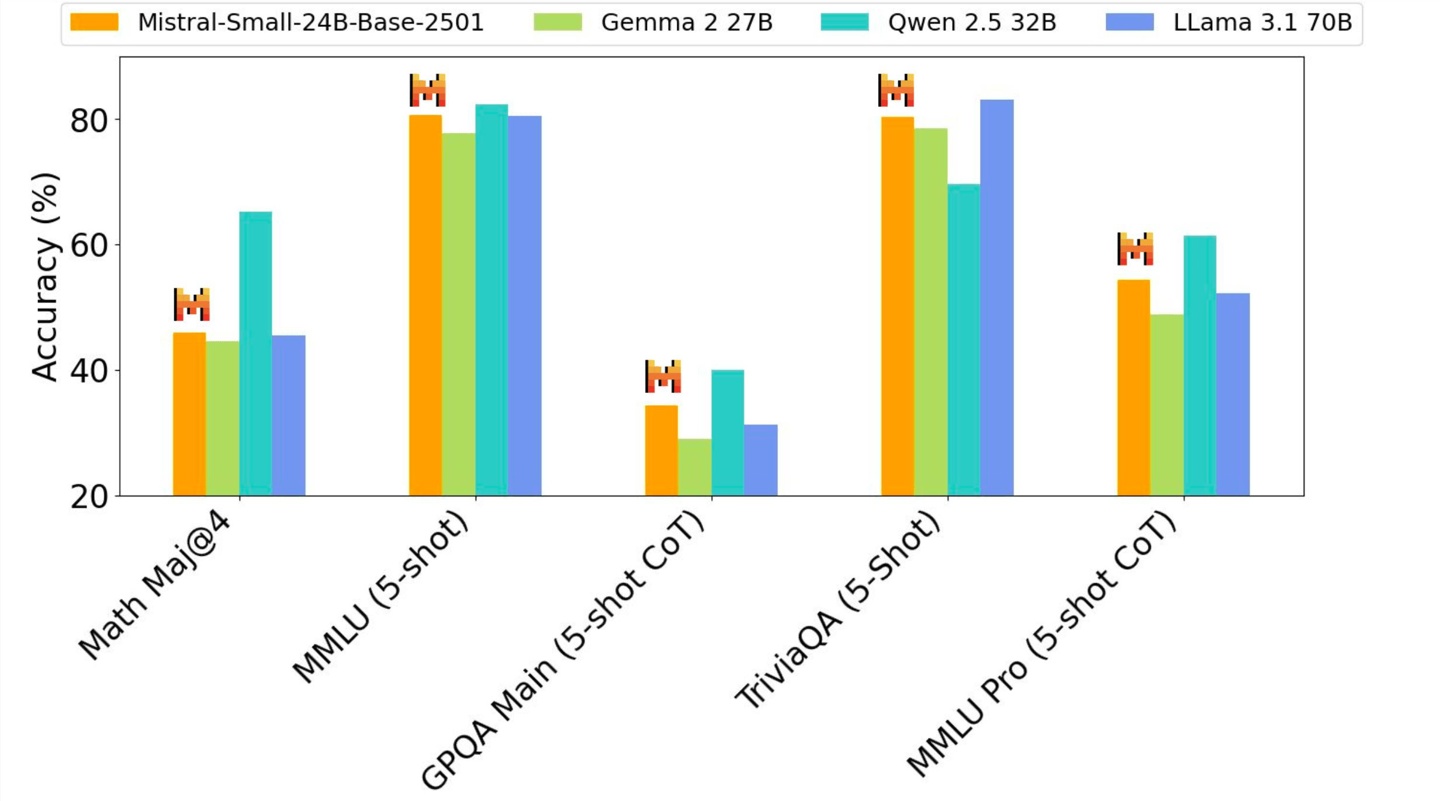
Mistral-Small 模型在多个基准测试中表现出色,在特定任务中甚至可以媲美或超越 Llama 3.3-70B 和 GPT-4o-mini 等更大规模的模型。
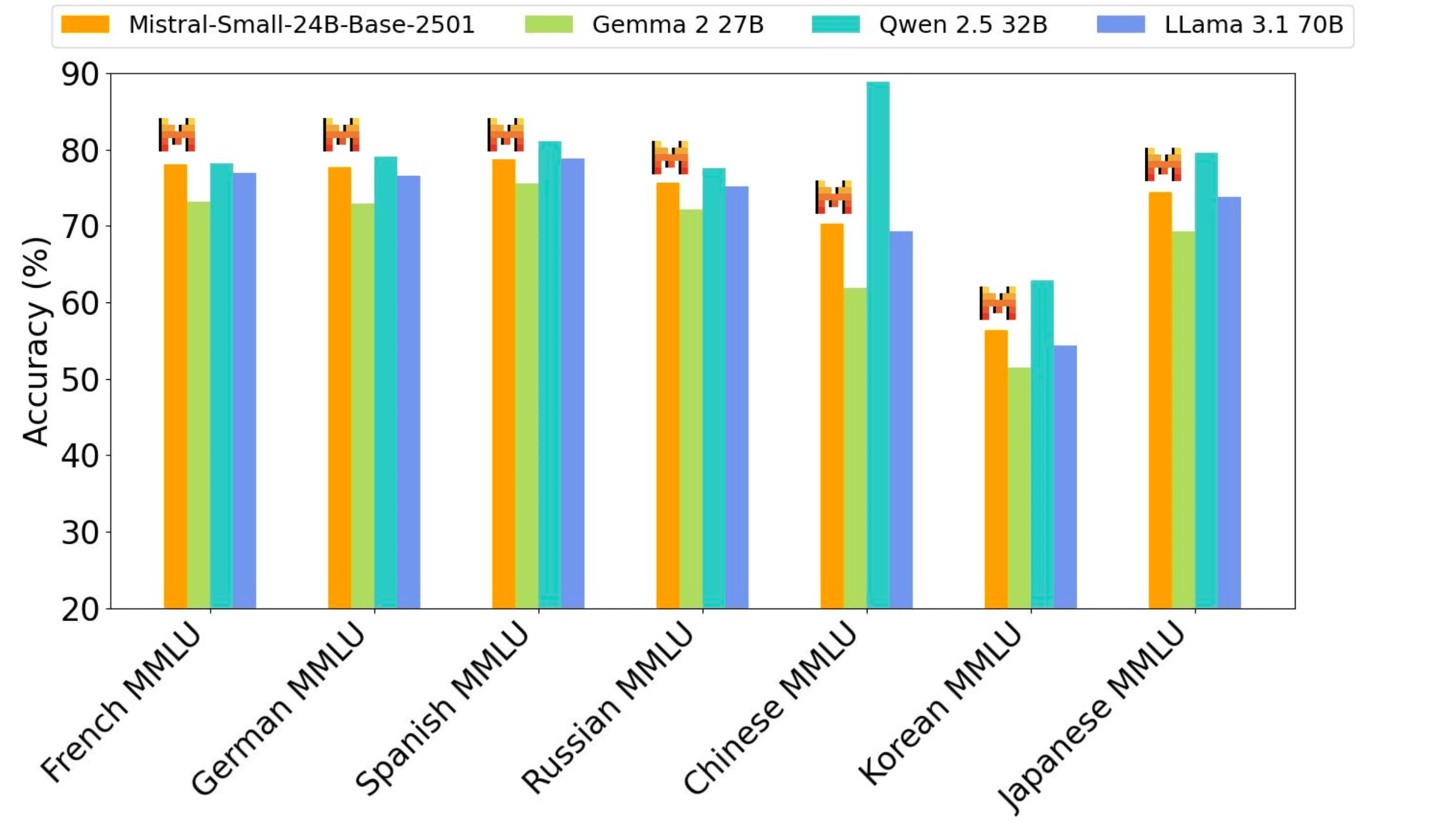
它在推理、多语言处理和代码基准测试中都达到了很高的准确率,例如在 HumanEval 上达到 84.8%,在数学任务上达到 70.6%,在 MMLU 基准测试中准确率超过 81%,每秒可处理高达 150 个 token。IT之家附上性能相关图片如下:
Mistral Small 3 针对以下应用进行了优化:
还没有评论,来说两句吧...