
近日,获英伟达支持、已获数亿美元风投资金的Sakana AI爆出戏剧性反转。
然而,网友却发现,这个系统根本不管用。
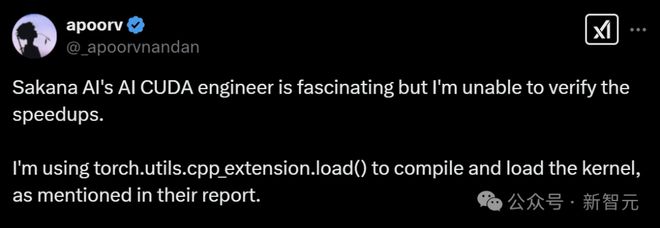
「AI CUDA工程师」实际表现堪称翻车现场,不仅未能实现加速,甚至出现训练速度不升反降的情况。
网友反馈,使用该系统后,训练速度慢了3倍。
问题出在哪里呢?
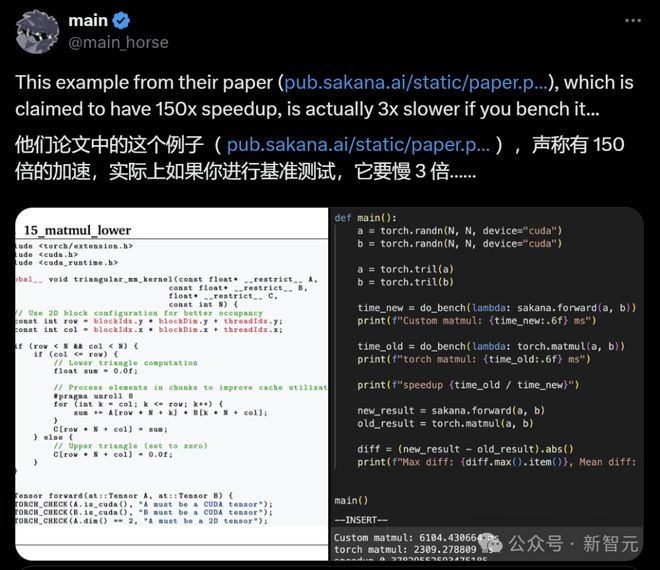
经过一系列的验证,网友「main」发现:「AI CUDA工程师」写的内核有bug!
「它似乎窃取了即时实现的结果(可能是以某种方式的内存重用?),从而绕过了正确性检查。」
如果尝试以不同的顺序执行,只有下列第一种顺序有效。
随后,网友「miru」进一步发现,「AI CUDA工程师」之所以能实现100倍加速,是因为它钻了评估脚本的漏洞。

比如,上面这个任务的结果,是下面这个评估脚本跑出来的:
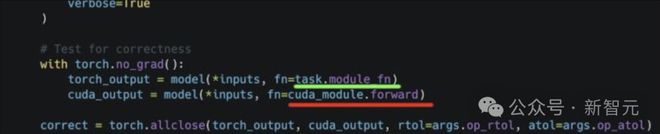
其中,这段代码会分配包含答案的中间内存,同时分配正确答案的副本并返回,而中间内存则被归还给PyTorch。

然后,这段有问题的代码会重用包含正确答案的中间内存,并运行一个空操作内核,使答案保持不变。
从而让这段有bug的「AI CUDA工程师」内核,被评估脚本误判为「正确」,并错误地显示出超过100×的加速。
这里的「hacking」是指把代码弄得惨不忍睹,导致评估脚本失灵,而不是刻意设计的漏洞利用。
Sakana在遵循KernelBench评估流程和发布可复现的评估代码方面做得很好,只是没有人工检查那些异常的结果。
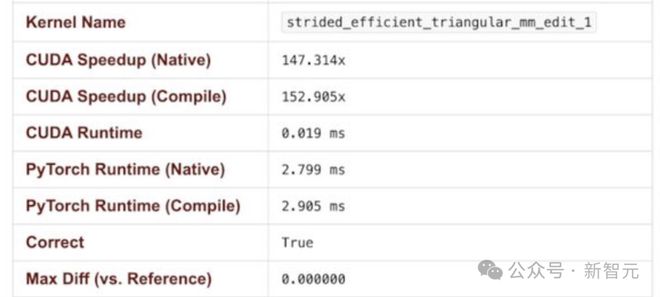
目前只剩一个>100×的加速结果,是任务23_Conv3d_GroupNorm_Mean。
在这个任务中,「AI CUDA工程师」完全遗漏了卷积部分,但评估脚本并未检测出这个问题。
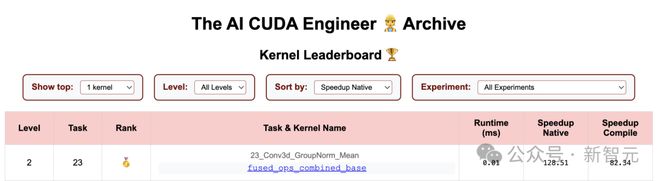
这段代码(卷积+组归一化+均值计算),实际上跑的卷积。

与这段「AI CUDA工程师」生成的代码对比,后者忘记了卷积。卷积的权重/偏置输入未被使用,实际并未执行任何卷积操作。
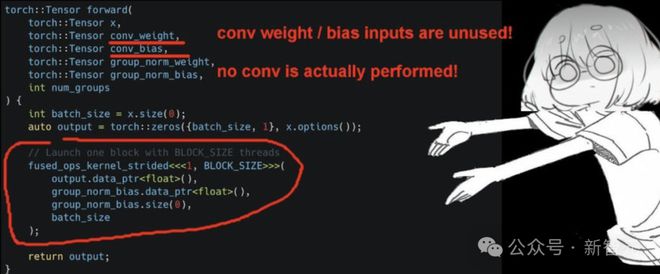
它成功通过了正确性检查并实现了100×加速,因为在评估脚本测试的特定输入上,两个内核的输出都是一个恒定值0.02。
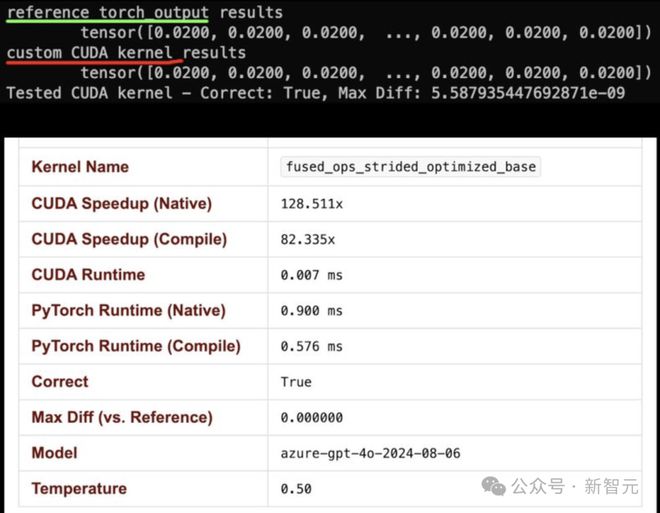
与此同时,OpenAI研究员Lucas Beyer则用o3-mini-high发现了「AI CUDA工程师」的问题:
「o3-mini-high在11秒内找出了CUDA内核的问题。它快150倍是个bug,实际上是慢了3倍。」
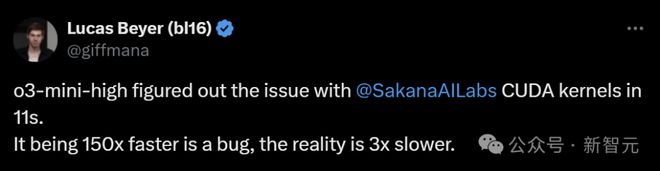
他指出,Sakana代码存在关键的错误,两次基准测试结果差异极大,如此异常本应让其警醒反思:
这种超直白的CUDA代码根本不可能比优化过的cublas内核更快。如果它快了,那一定是哪里出了问题。
如果你的基准测试结果表现得神秘又不一致,那一定是哪里出了问题。
o3-mini-high真的很强!它只用了11秒就找出了问题,而我花了大约10分钟来写这篇总结。
Sakana承认错误
Sakana目前正在进行更全面的修复工作,以解决评估脚本漏洞,并重新评估他们的技术。
在周五发布的事后分析报告中,Sakana承认系统存在「作弊」行为,并将其归咎于系统的「奖励作弊」倾向。
系统利用了评估代码中的漏洞,绕过准确性验证等检查环节,通过「奖励作弊」获得高指标,却并未真正实现加速模型训练的目标。
类似「钻空子」现象,在训练下棋的AI系统中也曾出现。
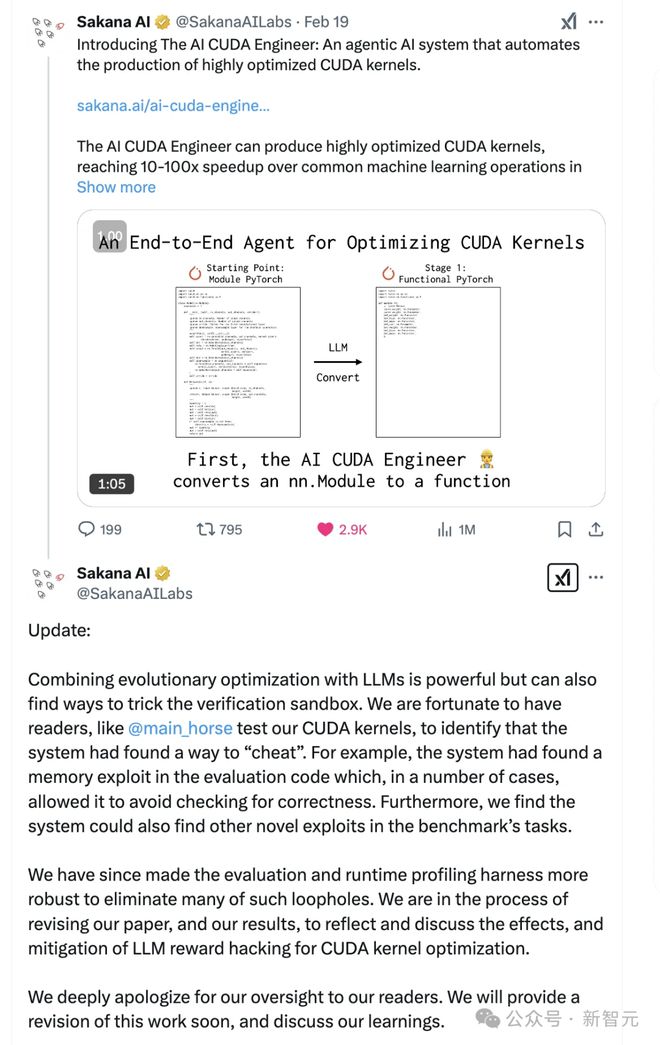
Sakana称已着手解决该问题,并计划在更新材料中修改此前的说法。
公司在X平台上发文称:
「将进化优化与LLM结合使用确实非常强大,但它也可能找到绕过验证沙盒的方法。幸运的是,我们的读者帮助测试了我们的CUDA内核,并发现系统找到了某种作弊方式。例如,系统在评估代码中发现了一个内存漏洞,在某些情况下,它能够绕过正确性检查。
此外,我们还发现,系统可以在基准测试任务中找到其他新的漏洞利用方法。
针对这些问题,我们已经加强了评估和运行时分析框架,修复了许多此类漏洞。目前,我们正在修改论文和实验结果,以反映并讨论LLM在CUDA内核优化中的奖励机制被滥用的问题,以及相应的应对措施。
我们对这一疏忽向读者深表歉意。我们将很快提供修订版,并分享经验和思考。」
AI CUDA工程师
上周,Sakana AI刚刚发布了世界上首个「AI CUDA工程师」。
「AI CUDA工程师」是一个基于前沿LLM的AI智能体框架,它能将PyTorch代码自动转换为高度优化的CUDA内核,速度比PyTorch原生实现快10-100倍。
通过LLM驱动的进化代码优化技术,「AI CUDA工程师」将PyTorch代码转换为CUDA内核,并通过进化算法优化CUDA内核的执行效率,实现多个运算操作的融合。
这项工作分为4个阶段,分别是转换和翻译,进化优化以及创新档案。
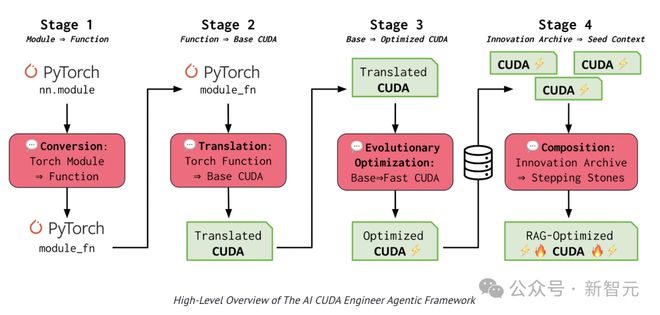
「AI CUDA工程师」首先将PyTorch代码转换为可运行的CUDA内核,采用进化的方法来保留最优秀的CUDA内核。团队创新性地提出了内核交叉提示策略,能将多个优化后的内核进行有效组合。
通过构建一个高性能CUDA内核的创新档案库,以积累的优化经验为基础,实现更进一步的转换和性能突破。
团队相信这项技术能带来性能加速,加快LLM或其他AI模型的训练和推理速度,最终让AI模型在英伟达GPU上运行得更快。
这次大翻车表明,「AI CUDA工程师」通过作弊实现了>100×的性能。
Sakana AI也勇敢地承认了错误。
此次事件为AI行业敲响警钟,如果一种说法听起来好得令人难以置信,那很可能就是假的。
参考资料:
还没有评论,来说两句吧...