
金磊 发自 凹非寺
量子位 | 公众号 QbitAI
开源周的第三天,DeepSeek把训练推理V3/R1背后的“动力”给亮出来了——
DeepGEMM:一个FP8 GEMM(通用矩阵乘法)库,支持密集(dense)和混合专家(MoE)矩阵乘法运算。
我们先来简单了解一下GEMM。
GEMM,即通用矩阵乘法,是线性代数中的基本运算,是科学计算、机器学习、深度学习等领域中“常客”,也是许多高性能计算任务的核心。
但由于它的计算量往往都比较大,所以GEMM的性能优化是至关重要的一点。
而DeepSeek这次开源的DeepGEMM,依旧是保持了“高性能+低成本”的特性,亮点如下:
简单来说,DeepGEMM主要用于加速深度学习中的矩阵运算,特别是在大规模模型训练和推理中,它特别适用于需要高效计算资源的场景,能够显著提升计算效率。
很多网友们对这次的开源都比较“买单”,有人将DeepGEMM比作数学界的超级英雄,认为它比飞快的计算器还要快,比多项式方程还要强大。
也有人将DeepGEMM的发布比喻为量子态稳定到一个新的现实,称赞其即时编译的干净利落。
当然……也有人开始担心起自己手上的英伟达股票了……
深入了解DeepGEMM
DeepGEMM是一个专门为实现简洁高效的FP8通用矩阵乘法(GEMMs)而打造的库,它还具备细粒度缩放功能,这一设计源于DeepSeek V3。
它既能处理普通的通用矩阵乘法,也能支持MoE分组的通用矩阵乘法。
这个库是用CUDA编写的,安装的时候不需要编译,因为它会在运行时通过一个轻量级的即时编译(JIT)模块来编译所有的内核程序。
目前,DeepGEMM只支持英伟达的Hopper张量核心。
为了解决FP8张量核心在计算累积时不够精确的问题,它采用了CUDA核心的两级累积(提升)方法。
虽然DeepGEMM借鉴了CUTLASS和CuTe里的一些理念,但并没有过度依赖它们的模板或代数运算。
相反,这个库设计得很简洁,只有一个核心内核函数,代码量大概300行左右。
这使得它成为一个简洁易懂的资源,方便大家学习Hopper架构下的FP8矩阵乘法和优化技术。
尽管其设计轻巧,但DeepGEMM的性能可以匹配或超过各种矩阵形状的专家调优库。
那么具体性能如何呢?
团队在H800上使用NVCC 12.8测试了DeepSeek-V3/R1推理中可能使用的所有形状(包括预填充和解码,但没有张量并行)。
下面这张图展示的是用于密集模型的普通DeepGEMM的性能:
从测试结果来看,DeepGEMM计算性能最高可达1358 TFLOPS,内存宽带最高可达2668 GB/s。
加速比方面,与基于CUTLASS 3.6的优化实现相比,最高可达2.7倍。
再来看下DeepGEMM支持MoE模型的连续布局(contiguous layout)的性能:
以及支持MoE模型掩码布局(masked layout)的性能是这样的:
如何使用?
要想使用DeepGEMM,需先注意一下几个依赖项,包括:
Development代码如下:
# Submodule must be clonedgit clone --recursive :deepseek-ai/DeepGEMM.git# Make symbolic links for third-party (CUTLASS and CuTe) include directoriespython setup.py develop# Test JIT compilationpython tests/test_jit.py# Test all GEMM implements (normal, contiguous-grouped and masked-grouped)python tests/test_core.py
安装代码如下:
python setup.py install
在上述步骤之后,您的Python项目中导入deep_gemm即可。
接口方面,对于普通的DeepGEMM,可调用deep_gemm.gemm_fp8_fp8_bf16_nt函数,支持NT格式(非转置LHS和转置RHS)。
对于分组的DeepGEMM,连续布局情况下是m_grouped_gemm_fp8_fp8_bf16_nt_contiguous;掩码布局情况下是m_grouped_gemm_fp8_fp8_bf16_nt_masked。
DeepGEMM还提供设置最大SM数量、获取TMA对齐大小等工具函数;支持环境变量,如DG_NVCC_COMPILER、DG_JIT_DEBUG等。
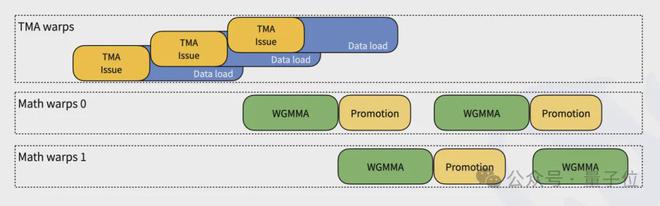
除此之外,DeepSeek团队还提供了几种优化的方式,包括:
还没有评论,来说两句吧...