
由加密货币、代币、积分、礼物或其他赠品等奖励所激励的活动
在上述讨论的所有三种情况下,研究者认为这些购买、交换或受激励而获得的 GitHub star是虚假的,因为它们是人为抬高的,并不真正代表真实GitHub用户对仓库的任何真实赞赏、使用或收藏。
StarScout设计
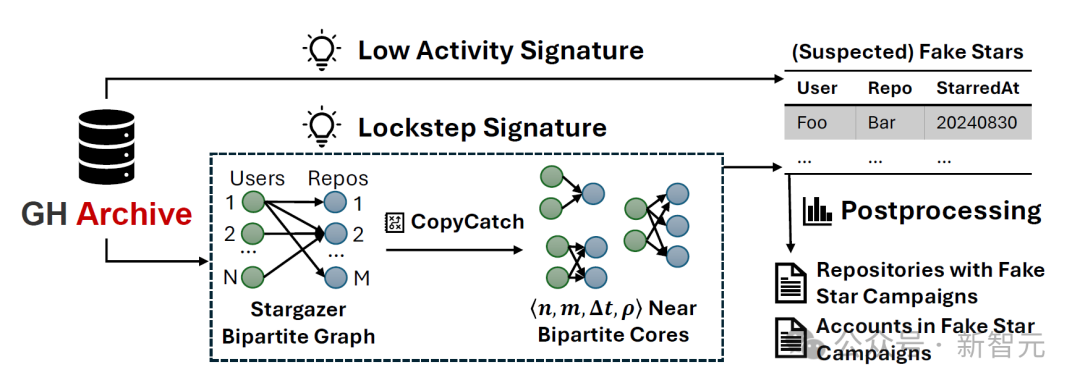
StarScout的概述图
从整体上看,StarScout在GHArchive上应用分布式算法,以从GitHub历史中定位两种异常star行为的特征:低活动特征和同步特征,这两者很可能与虚假star相关。
具体来说,低活动特征用于识别那些对一个或几个代码仓库star后便不再活跃的账户的stars;而同步特征识别来自n个账户集群的stars,这些账户在短的∆t时间窗口内反复一起对另一个包含m个仓库的集群进行star。
在虚假star与真实star之间划定明确边界并不容易,某些特殊情况,例如一个GitHub教程仓库要求读者为其点star作为教程的一部分,会增加这种区分的复杂性。
StarScout使用一个由用户和代码仓库组成的双向图(Stargazer Bipartite Graph)来处理这些特征的检测。
在低活动特征的检测中,StarScout会识别仅有一个WatchEvent(即只为一个GitHub仓库点star)以及在同一天最多一个附加事件(如ForkEvent)的账户。
尽管被检测的账户可能是由虚假star商控制的一次性机器人账户,但也可能是误判的真实用户,例如某人本来是合法注册的真实账户,但是在为一个仓库点star后就将自己的GitHub搁置了。
为了缓解这一问题,StarScout只考虑那些至少拥有50个被怀疑为虚假star的代码仓库。
这种行为是GitHub star商无法规避的,因为无论他们采用何种混淆方法,这些账户通常都是新注册的一次性账户,或者是在短时间内为多个仓库点star以满足交付承诺。
从数学角度来看,GitHub上的所有star可被建模为一个二分图:每个用户和代码仓库是一个节点,它们的star关系构成边,而star时间则作为边的属性。
如果一个虚假star商控制了一组n个账户,在承诺的交付时间内为m个代码仓库点star,那么它们将在star双向图中留下所谓的时间上连贯的近似二分核。
之前的一些研究也已表明,这种近似二分核于在线社交网络中很难自然形成,并且与欺诈活动高度相关。
然而,找到最大二分核的问题是NP难的。
因此,StarScout重新实现了CopyCatch,这是一种最先进的分布式局部搜索算法,曾用于Facebook检测虚假点赞。通过该算法,StarScout检测GitHub star双向图中的近似二分核。
CopyCatch从一组种子仓库(所有具有≥50颗star的仓库)开始;然后它迭代地生成一个时间中心,并增加n和m,为每个种子仓库在该时间中心内找到一个局部最大的近似二分核。最后,大于预定义n和m阈值的二分核将被视为虚假star。
虽然处理低活动特征和同步特征的两种启发式方法能够识别GitHub star数据中的显著异常模式,但并不能假定每个获得虚假star的代码仓库都是主动去获取这些star的。
例如,对于非常受欢迎的代码仓库,虚假star可能显得毫无意义。但免不了虚假账户可能故意为流行代码仓库点star,以规避平台检测。因此,后处理步骤旨在仅保留那些因虚假star激增而受益显著的代码仓库。
为此,StarScout汇总了每月的star数,并寻找符合以下条件的代码仓库:
(1) 至少有一个月获得超过50个虚假star,且虚假star比例超过50%;
(2) 所有时间段的虚假star比例(相对于所有star)超过10%。
StarScout将这些代码仓库视为发起虚假star的代码仓库,并将激增月份中点star的账户标记为参与虚假star活动的账户。
最终,StarScout在22,915个代码仓库中检测到453万个虚假star,这些star由132万个账户创建。

截至2024年10月,StarScout检测到并已在GitHub上删除的仓库/账户的百分比
与基准删除比例(仓库为5.84%,用户为4.43%)相比,已检测的仓库和账户的删除比例异常较高:虚假star活动中大约91%的仓库和62%的疑似虚假账户已被删除。

通过对GitHub事件分布的比较分析,研究人员发现,存在虚假star活动的仓库和账户往往更倾向于单一的star操作,其他类型活动事件的数量相较于普通仓库明显更少。
而且就算是在star活动数量上两者相近,但存在虚假star活动的账户和仓库通常仅有少量的Fork、Push和Create活动,而几乎没有Issue、PR和Comment活动。这主要是因为后三种活动相较于前三种活动更难以伪造。
假star真能以假乱真,提高热度吗?
研究者也对于假star是否能够像真star一样拥有「马太效应」进行了研究。
研究的目的探索假stars是否也能通过提高热度,以假乱真来吸引更多的用户去给出真实的star。
他们针对GitHub stars的影响制定了以下两个假设:
H1:积累真实的GitHub星级将有助于GitHub仓库在未来获得更多真实的 GitHub 星级。
H2:积累虚假的GitHub星级将有助于GitHub仓库在未来获得更多真实的GitHub星级,但效果不如真实星级强。
为了检验这两个假设,研究者通过向模型添加固定效应或随机效应项,稳健地估计了自变量对未观测到的异质性(即可能影响结果变量但未在模型中测量的因素)的纵向影响。
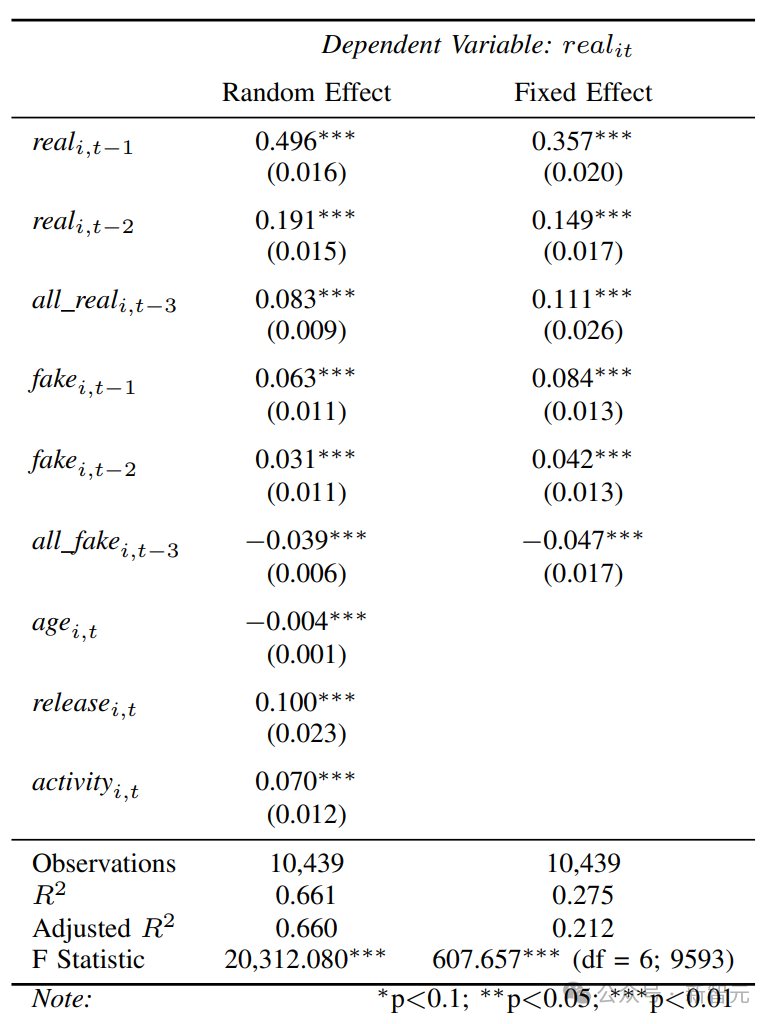
从上表中可以看出,H1假设得到了明确支持:根据固定效应模型,在保持所有其他变量不变的情况下,月t-1真实stars增加1%与月t真实星级预期增加0.36%相关。
类似地,也可以预测出从月t到月t+1真实stars能够增加0.36%。而该效应在月t+2则降至0.15%,在随后的所有月份降至0.11%,但效应始终为正。
换句话说,拥有更多真实stars的仓库在未来往往也会获得更多真实stars,这与社交网络中普遍存在的「富者愈富」现象相呼应。
另一方面,H2假设仅得到部分支持:在保持所有其他变量不变的情况下,月t虚假stars增加1%与月t+1真实stars预期增加0.08%以及月t+2真实stars预期增加0.04%相关。
换句话说,虚假stars在接下来的两个月内对吸引真实星级确实具有统计学上显著且纵向递减的正向效应,但该效应比真实星级的效应小三到四倍。
然而,月t虚假stars增加1%与月t+2及之后所有月份真实星级平均预期减少0.05%相关。
总的来讲,购买假star可能在短期内(即两个月以内)能够帮助一个仓库获得真实的关注,但其效果比真实的star小3到4倍。而且从长期来看,这种做法无疑也会产生深远的负面影响。
最后,研究者强调,GitHub库的star指标并不是一个可靠的高质量指标,所以至少不能是高风险决策的单一参考指标。
同时,研究者也建议开发者不要为推广自己的项目而去伪造star,因为这其实无济于事。
相反,他们建议在开源领域工作的存储库维护者和初创公司创始人应该战略性地专注于促进实际项目的进步,而不是表面上夸大star的数量。也就是说如果项目实际上并不是高质量的和维护良好的,那么即使高star可能会在短期内增加项目的可见度,也终究会迅速被大家排斥。
还没有评论,来说两句吧...