
OpenAI的o3 模型发布之后引发的群体狂热是我们未曾见过的景象。
有些人确实撑不住,选择放弃计算机科学职业,因为他们觉得这些技能在人工智能时代很快就不再是必需的了。
但这一切都只是彻头彻尾的耸人听闻。
这是这个行业最糟糕的一面:人工智能网红对难以辨别的大量不必要的炒作推波助澜,他们为了将点击变现而不择手段,但在我看来,他们就像彻头彻尾的骗子,往好处说也是无知。
这篇文章我会解释为什么这是无稽之谈,以及为什么 2025 年不会有任何人因为 o3 而失业。
下面我们就来深入探讨一下。
一则公告,令人印象深刻,但又有点微妙
随着 OpenAI 发布最新的大推理模型 (LRM) o3 的消息尘嚣日渐散去,现实开始慢慢显现。
历史性时刻
是的,表明上看,这个模型令人印象深刻,深刻到让你怀疑明年还能不能找到工作。
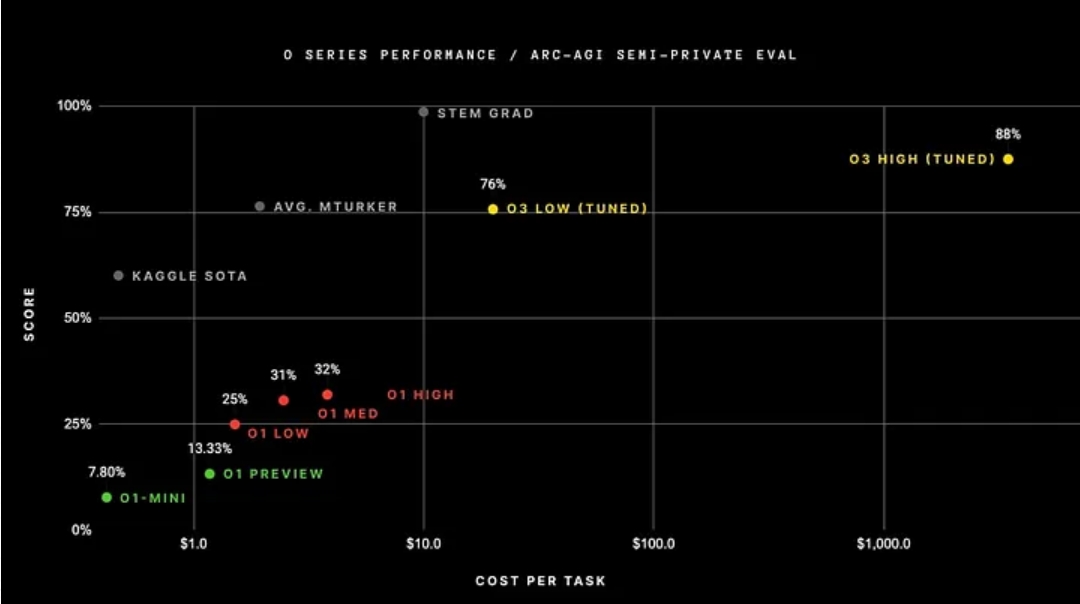
O3在众多基准测试都取得了惊人成果,但其中一项特别引人关注:o3在 ARC-AGI 公共基准测试中,在高计算阈值(允许模型思考更长时间)下的准确率为 87.5%。
AI执行抽象推理任务(识别网格对象存在的微妙模式并应用到新例子)的成绩超过了普通人类,这是有史以来的第一次。
测试主要涉及到智能的两个关键方面:
即时习得技能。换句话说,受试者是否能即时地学习新的模式。
学习效率,即受试者是否能仅通过几个例子就学会新的模式。
一个AI模型能够成功完成这一挑战确实值得称道,但结果远不止眼前所见那么简单。
未提及的微妙之处
虽说结果不能反映现实确实有点太绝对,但也不至于像AI网红说得那么可怕。
假设有两个孩子参加考试。其中一个仔细思考了 20 多分钟就答对了 80%。另一个孩子答对了 90%,但却是花了整整两个月的时间才完成考试。
哪个孩子更聪明?是 20 分钟内答对 80% 的?还是花了两个月时间才拿得到更好成绩的那位?
在我看来,智力不只是裸价值那么简单,效率也很重要。但在效率方面,人工智能仍然非常非常糟糕。
据业内人士透露,基准测试的时候o3完成一项任务的平均处理成本为5000美元。
用大白话来讲,在解决一个人类最多需要几分钟就能搞定的网格模式问题时,o3平均每项任务要花费 5700 万个Token(词元,约相当于 4000 多万个单词),总计花费 5000 美元。
也就是说,o3 等大推理模型 (LRM) 是在用大得荒谬计算和资金,让解决问题的游戏变成一种只要算力足够就能找到正确答案的游戏。
而且这还没将高达 5 亿美元的模型训练成本考虑在内,所以总数可能连巴菲特看了都要头晕。
我想说明的是,像 o3 这样的人工智能要想对社会产生真正影响,就得大幅提高智能效率,或者说提高“智能”/算力比。
但这个效率怎么计算呢?
位数/字节比
标准大语言模型 (LLM)主要的性能指标是perplexity(困惑度)。通俗地说,它衡量的是模型给人的“惊喜程度”,或者说它对预测下一个单词的信心有多大。
如果困惑度下降,这意味着它对这个词应该是什么更有信心(用分配给所选单词的信心概率来衡量)。
但LRM 的主要指标是位数/字节比(bits per byte, BpB )。
新指标的出现
ByB测量每个生成的词元或单词所传递的信息“量”多寡。
LLM回答的时候如果用LRM来生成推理和响应词元,每个任务生成的词元数量要大得多。这时候光准确预测出下一个单词已经不够了,这个单词还必须具有相关性,好让模型可以逐渐减少生成的词元数量。
o3 在 ARC-AGI 测试中拿得到了近 90% 的准确率令让人欣慰,但你会发现它每个问题都要生成数百万个词元,而人类顶多生成 100 到 200 个词元就够了(如果能这么比的话)。
所以,如果想真正衡量像 o3 这样的 o 型模型的智能,我们不仅要衡量响应的质量,还要衡量模型创造价值的效率。
这就是为什么BpB是好指标的原因所在;o3的响应通常是正确的,但BpB(即每个生成词元的信息量)却低得离谱。用前面的类比,人类是 20 分钟内拿到 80% 正确率的小孩;人工智能击败了我们(只是有时候能),但却需要用相当于“人类一辈子”的时间才能做出响应。
但问题还不止这个。就像顶级人工智能研究员 Miles Cranmer 所指出那样,o 型模型似乎也没改善会出现幻觉的现象。
事实上,用户体验其实是更糟了,因为模型犯错的次数比以前多多了,仿佛它对自己的知识变得更自负了。
其结果是o 型模型的体验不仅昂贵,而且可能会导致代价高昂的错误。
沉住气
对于人工智能研究实验室来说,引用基准测试结果来跟其他实验室的产品做对比是很好的手段,因为可以反映自家模型的实用性和“智能”程度,只不多远未能反映现实。
o3 的成绩仍值得肯定
o3在 ARC-AGI 或FrontierMath测试取得的成绩值得祝贺,原因非常重要:因为又一次给了我们希望,人类可能正朝着通用人工智能(AGI)的正确方向前进。
但说成是“征服了 AGI”就绝对错了。这种说法的意思是这些模型比实际要聪明得多;但论起智能效率,它们还是比小孩要笨,而 o3的结果并没有改变这一点。
事实上,它们进一步证实了这一点:o3 需要数百万美元才能通过某项基准测试,因为他们必须生成数百万个词元才能解决某个具有挑战性的网格模式查找问题。
这不是AGI,这只是证明了只要有足够的算力,AI 模型确实就能取得显著成绩(再次强调,更大算力可以带来更好结果才是真正的胜利)。
无论如何,o3 必须被看作计算似乎是解锁智能的关键这个观点的证明,但我们距离我们希望用这些系统开发出的真正智能还很远(甚至 OpenAI 也承认这一点)。
话虽如此,我们有理由对此保持乐观:ChatGPT 自推出以来已将处理成本降低了 100 倍。此外,尽管 o3-mini 更加“智能”,但运行成本却比 o1-mini 还要低。
换句话说,我们确实在改进BpB指标,但实际情况是,这个过程将比人们想象的要长得多。
那我们的工作会不会受影响呢? 影响因素是什么?
呃,其实很简单:钱。
激励机制就是一切
这种模型为什么无法真正打入劳动力市场?原因无非是成本。想想看:
当然不会!
如果o3的价格降至零,人人都将拥有一个可以解决某些最困难数学问题的模型。
至于解决过程是不是靠死记硬背和大量“思考”,你不会关心,你只关心结果。但现在,如果你要大规模部署 o3 的话,几天之内公司就会破产。
人工智能的真相及如何探索机器智能
目标从来都不是——也永远不会是——打造真正的智能;目标一直是让机器智能的成本低于人类智能。
如果人工智能实验室实现了这一点,我们就可以提出这些工具是否会取代部分人类的问题了(再次强调,把人工智能说成是所有人类员工的替代品,这属于一种很廉价的恐吓言论)。
虽然 LLM 已经实现了这种逆转,但它们却愚蠢至极。一旦 LRM 变得比雇佣人类还要便宜,真正的解锁人才会出现。o3 确实有可能让自问是否需要多一位软件开发人员,还是说付点订阅费并把工具交给原来那位高级软件开发者更划算。
这样的问题即将浮现,但这些数字 2025 年会不会增加呢?我是高度怀疑的,尤其是考虑到各家人工智能实验室在算力和能源方面受到的限制。
那它算 AGI 吗?
不要再讲这些可笑的话了
过去几天我在社交媒体上看到无数声称 o3 是 AGI 的说法,因为它在 ARC-AGI 公共基准测试中取得了显著成绩。
我就直说了吧:这不是事实,这种说法令人尴尬。
这些说法的依据是以下二者之一:要么是无知,要么是为了吸引注意力的耸人听闻;甚至连 OpenAI 都不敢提出这样的主张。
但无论如何,o3 值得庆贺,因为这是奖励工程努力的一次突破。与过去的 AlphaGo 或AlphaStar一样,这一模型在奖励可验证领域(即可以自动验证奖励函数的领域,如编码或数学)实现了超人壮举。
不过,o3 是第一个实现奖励通用性的模型,也就是说,一个用单一数据分布训练出来的模型在多个领域(同样是可验证的领域)上取得超人成果。这很疯狂,但它不是AGI。要实现 AGI,这个奖励函数(或多个函数)应该推广到可奖励无法自动计算的其他领域;这是人工智能的圣杯,但尚未实现。
AGI 也须考虑经济因素。用大白话来说,智能的成本必须低于人类的成本,这样实现才具有经济意义。
为了实现 AGI,我们需要以下两件事之一:将Token成本降至接近零(算力成本和能源成本)或找到让 AI 更快、更便宜地解决问题的方法(提高BpB指标,也就是算法上取得突破)。
o3 模型给了我们希望,也就是算力增加会继续得到更好的“智能”,但是这是靠测试时的计算而不是靠增加预训练预算来达到的。
但我们不要再假装它是某个自己不属于的东西(AGI)了。
译者:boxi。
还没有评论,来说两句吧...